SQL
登录MySQL数据库
1 | mysql -u root -p |
导入.sql数据库文件
1 | USE RUNOOB; |
SELECT
SELECT语句用于从数据库中选取数据,结果存储在一个结果表中,成为结果集。
1 | SELECT column_name, column_name FROM table_name; |
1 | SELECT * FROM table_name; |
从"Websites"表中选取所有列:
1 | SELECT * FROM Websites; |
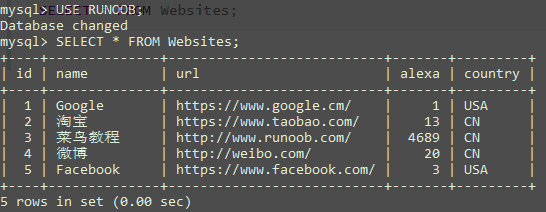
从"Websites"表中选取"name"和"country"列:
1 | SEKECT name, country FROM Websites; |
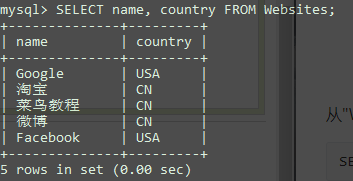
SELECT DISTINCT
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。DISTINCT 关键词用于返回唯一不同的值。
1 | SELECT DISTINCT column_name, column_name FROM table_name; |
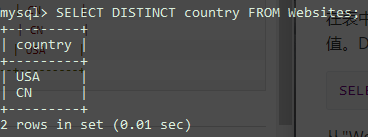
从"Websites"表中选取"country"列中唯一不同的值,也就是去掉"country"列重复值:
1 | SELECT DISTINCT country FROM Websites; |
WHERE
WHERE子句用于过滤记录,提取那些满足指定条件的记录。
1 | SELECT column_name, column_name |
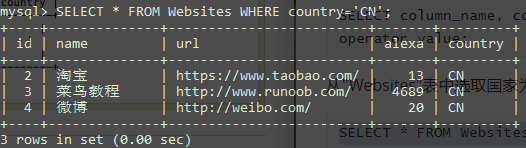
从"Websites"表中选取国家为"CN"的所有网站:
1 | SELECT * FROM Websites WHERE country='CN'; |
从"Websites"表中选取id为1的所有网站:
1 | SELECT * FROM Websites WHERE id=1; |
WHERE子句中的运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
BETWEEN
1 | SELECT column_name(s) |
选取id在2到4之间的所有网站:
1 | # 包括id=2和id=4 |
选取id不在2到4之间的所有网站:
1 | SELECT * FROM Websites WHERE id NOT BETWEEN 2 AND 4; |
LIKE
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
1 | SELECT column_name(s) |
选取name以字母’G’开头的所有网站:
1 | SELECT * FROM Websites WHERE name LIKE 'G%'; |
IN
IN操作符允许在WHERE子句中规定多个值。
1 | SELECT column_name(s) |
选取name为"Google"或"菜鸟教程"的所有网站:
1 | # IN |
ORDER BY
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
1 | SELECT column_name,column_name |
从 “Websites” 表中选取所有网站,并按照 “alexa” 列升序(降序)排序:
1 | SELECT * FROM Websites ORDER BY alexa ASC(DESC); |
INSERT INTO
INSERT INTO 语句用于向表中插入新记录。
1 | INSERT INTO table_name VALUES (value1,value2,value3,...); |
1 | INSERT INTO table_name (column1,column2,column3,...) |
向 “Websites” 表中插入一个新行:
1 | INSERT INTO Websites (name, url, alexa, country) |
在指定的列插入数据:
1 | INSERT INTO Websites (name, url, country) |
完成上述2个插入操作后,数据表如下:
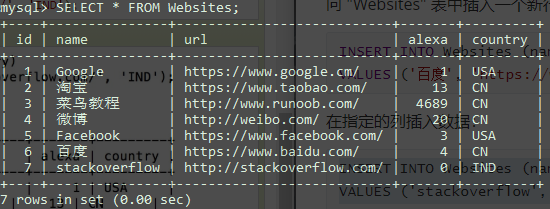
UPDATE
UPDATE 语句用于更新表中已存在的记录。
1 | UPDATE table_name |
如果没有WHERE子句,所有的记录都将被更新!
把’菜鸟教程’的alexa排名更新为5000, country更新为USA:
1 | UPDATE Websites |
DELETE
DELETE 语句用于删除表中的行。
1 | DELETE FROM table_name WHERE some_column=some_value; |
如果没有WHERE字据,所有的记录都将被删除!
从 “Websites” 表中删除网站名为 “Facebook” 且国家为 USA 的网站:
1 | DELETE FROM Websites WHERE name='Facebook' AND country='USA'; |
删除所有数据
在不删除表的情况下,删除表中所有的行。这意味着表结构、属性、索引将保持不变:
1 | DELETE FROM table_name; |
SELECT TOP, LIMIT, ROWNUM
用于规定要返回的记录的数目。
1 | # mysql |
1 | # SQL Server/MS Access |
1 | # Oracle |
从"Websites"表中选取前2条记录:
1 | SELECT * FROM Websites LIMIT 2; |
通配符
通配符可用于替代字符串中的任何其他字符,通常与LIKE一起使用。
| 通配符 | 描述 |
|---|---|
| % | 替代0个或多个字符 |
| _ | 替代1个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist]或[!charlist] | 不在字符列中的任何单一字符 |
选取url包含’oo’开始的所有网站:
1 | SELECT * FROM Websites WHERE url LIKE '%oo%'; |
选取 name 以 “G” 开始,然后是一个任意字符,然后是 “o”,然后是一个任意字符,然后是 “le” 的所有网站:
1 | SELECT * FROM Websites WHERE name LIKE 'G_o_le;' |
MySQL使用REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
选取 name 以 “G”、“F” 或 “s” 开始的所有网站:
1 | SELECT * FROM Website WHERE name REGEXP '^[GFs]'; |
选取 name 不以 A 到 H 字母开头的网站:
1 | SELECT * FROM Website WHERE name REGEXP '^[^A-H]'; |
别名
为表名称或列名称指定别名。
1 | # 列的别名 |
JOIN
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
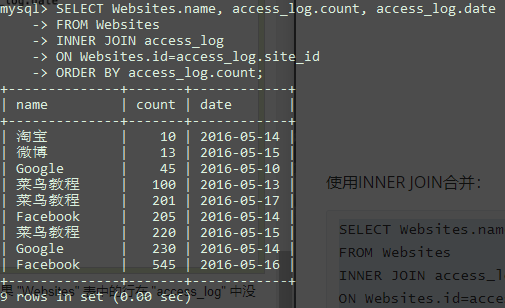
当前"Websites"表数据如下:
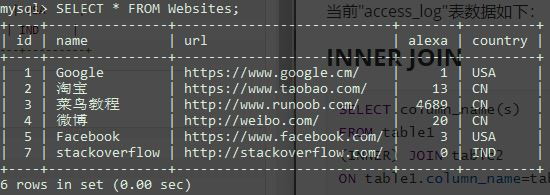
当前"access_log"表数据如下:
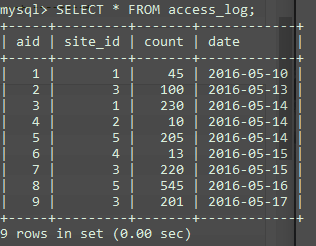
INNER JOIN
INNER JOIN同JOIN。
1 | SELECT column_name(s) |
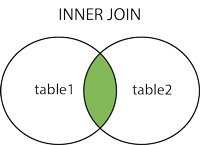
使用INNER JOIN合并:
1 | SELECT Websites.name, access_log.count, access_log.date |
LEFT JOIN
LEFT JOIN (在某些数据库中为LEFT OUTER JOIN)关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
1 | SELECT column_name(s) |
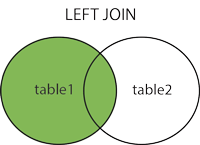
返回所有网站及他们的访问量(如果有的话),把 Websites 作为左表,access_log 作为右表:
1 | SELECT Websites.name, access_log.count, access_log.date |

RIGHT JOIN
RIGHT JOIN(在某些数据库中为RIGHT OUTER JOIN) 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
1 | SELECT column_name(s) |
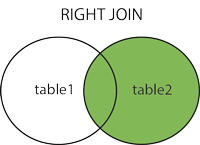
返回网站的访问记录,把 access_log 作为左表,Websites 作为右表:
1 | SELECT Websites.name, access_log.count, access_log.date |

FULL OUTER JOIN
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行。
1 | SELECT column_name(s) |
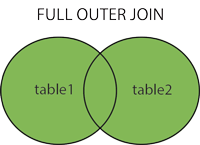
MySQL不支持FULL OUTER JOIN,SQL Server测试代码如下:
1 | SELECT Websites.name, access_log.count, access_log.date |
UNION
SQL UNION操作用于合并两个或多个SELECT语句的结果集。请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
1 | # UNION,UNION操作符选取不同的值,如果允许重复的值,使用UNION ALL |
当前"Websites"表数据如下:
当前"apps"表数据如下:

从"Websites"和"apps"表中选取所有不同的country:
1 | SELECT country FROM Websites |

从 “Websites” 和 “apps” 表中选取所有的country(也有重复的值):
1 | SELECT country FROM Websites |
使用UNION ALL从"Websites"和"apps"表中选取所有的中国的数据(也有重复的值):
1 | SELECT country, name FROM Websites WHERE country='CN' |

INSERT INTO SELECT
可以从一个表中复制所有的列插入到另一个已存在的表中:
1 | INSERT INTO table2 SELECT * FROM table1; |
或者复制希望的列插入到另一个已存在的表中:
1 | INSERT INTO table2 (column_name(s)) |
复制"apps"中的数据插入到"Websites"中:
1 | INSERT INTO Websites (name, country) |
只负责QQ的APP到"Websites"中:
1 | INSERT INTO Websites (name, country) |
CREATE DATABASE
CREATE DATABASE语句用于创建数据库。
1 | CREATE DATABASE dbname; |
CREATE TABLE
CREATE TABLE语句用于创建数据库中的表。
1 | CREATE TABLE table_name |
约束
SQL 约束用于规定表中的数据规则。如果存在违反约束的数据行为,行为会被约束终止。约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
1 | CREATE TABLE table_name |
在SQL中,有如下约束:
- NOT NULL:某列不能存储NULL值
- UNIQUE:某列的每行必须有唯一的值
- PRIMARY KEY:NOT NULL和UNIQUE的结合
- FOREIGN KEY:保证一个表中的数据匹配到另一个表中的值的参照完整性
- CHECK:保证列中的值符合指定的要求
- DEFAULT:规定没有给列赋值时的默认值
NOT NULL
强制"ID"列、"LastName"列以及"FirstName"列不接受NULL值:
1 | CREATE TABLE Persons ( |
在一个已创建的表的"Age"字段中添加NOT NULL约束:
1 | ALTER TABLE Persons MODIFY Age int NOT NULL; |
在一个已创建的表的 “Age” 字段中删除 NOT NULL 约束:
1 | ALTER TABLE Persons MODIFY Age int NULL; |
UNIQUE
UNIQUE 约束唯一标识数据库表中的每条记录。每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束。
在 “Persons” 表创建时在 “P_Id” 列上创建 UNIQUE 约束:
1 | # MySQL |
命名 UNIQUE 约束,并定义多个列的 UNIQUE 约束:
1 | CREATE TABLE Persons |
当表已被创建时,在 “P_Id” 列创建 UNIQUE 约束:
1 | ALTER TABLE Persons ADD UNIQUE (P_Id); |
命名 UNIQUE 约束,并定义多个列的 UNIQUE 约束:
1 | ALTER TABLE Persons |
撤销 UNIQUE 约束:
1 | # MySQL |
PRIMARY KEY
FOREIGN KEY
CHECK
DEFAULT
CREATE INDEX
CREATE INDEX 语句用于在表中创建索引。在不读取整个表的情况下,索引使数据库应用程序可以更快地查找数据。
在表上创建一个简单的索引。允许使用重复的值:
1 | CREATE INDEX index_name ON table_name (column_name); |
在表上创建一个唯一的索引。不允许使用重复的值:
1 | CREATE UNIQUE INDEX index_name ON table_name (column_name); |
DROP
删除索引:
1 | # MySQL |
删除表:
1 | DROP TABLE table_name; |
删除数据库:
1 | DROP DATABASE database_name; |
删除数据表内的数据:
1 | TRUNCATE TABLE table_name; |
ALTER TABLE
ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
在表中添加列:
1 | ALTER TABLE table_name ADD column_name datatype; |
在表中删除列:
1 | ALTER TABLE table_name DROP column_name; |
改变表中列的数据类型:
1 | # SQL Server/MS Access |
AUTO INCREMENT
Auto-increment 会在新记录插入表中时生成一个唯一的数字。
MySQL 使用 AUTO_INCREMENT 关键字来执行 auto-increment 任务。默认地,AUTO_INCREMENT 的开始值是 1,每条新记录递增 1。
1 | CREATE TABLE Persons |
让 AUTO_INCREMENT 序列以其他的值起始:
1 | ALTER TABLE table_name AUTO_INCREMENT=number; |
视图
视图是可视化的表
Date函数
NULL
1 | # IS NULL |
通用数据类型
数据类型定义列中存放的值的种类
函数
Aggregate函数计算从列中取得的值,返回一个单一的值:
- AVG()-返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
Scalar函数基于输入值,返回一个单一的值: